
Introduction
You asked your AI assistant a question - and it confidently gave you an answer. But here's the part nobody tells you: that answer might be months - or even years - out of date.
Every AI model has a "Knowledge Cutoff Date" - the point where its learning froze. After that, the world kept moving. New technologies launched. Elections happened. Companies merged. Regulations changed. But your AI? It stayed stuck in time.
Understanding this isn't optional anymore - it's critical. Whether you're a developer, a marketer, a student, or a business leader - knowing when your AI's knowledge expires can save you from costly, embarrassing mistakes.
What Exactly Is a Knowledge Cutoff Date?
Think of an AI model like a student who studied intensively for years, then locked themselves in a room. Everything they learned before entering that room? Crystal clear. Everything that happened outside after the door closed? Completely unknown.
A Knowledge Cutoff Date is the final date up to which an AI model's training data was collected. The model was trained on billions of texts, articles, books, and web pages - but only up to that specific moment in time.
Why Does This Matter?
If you ask an AI about a law that changed after its cutoff, a product that launched after its cutoff, or a person who rose to fame after its cutoff - it either won't know, or worse, will confidently give you outdated information as if it's current fact.
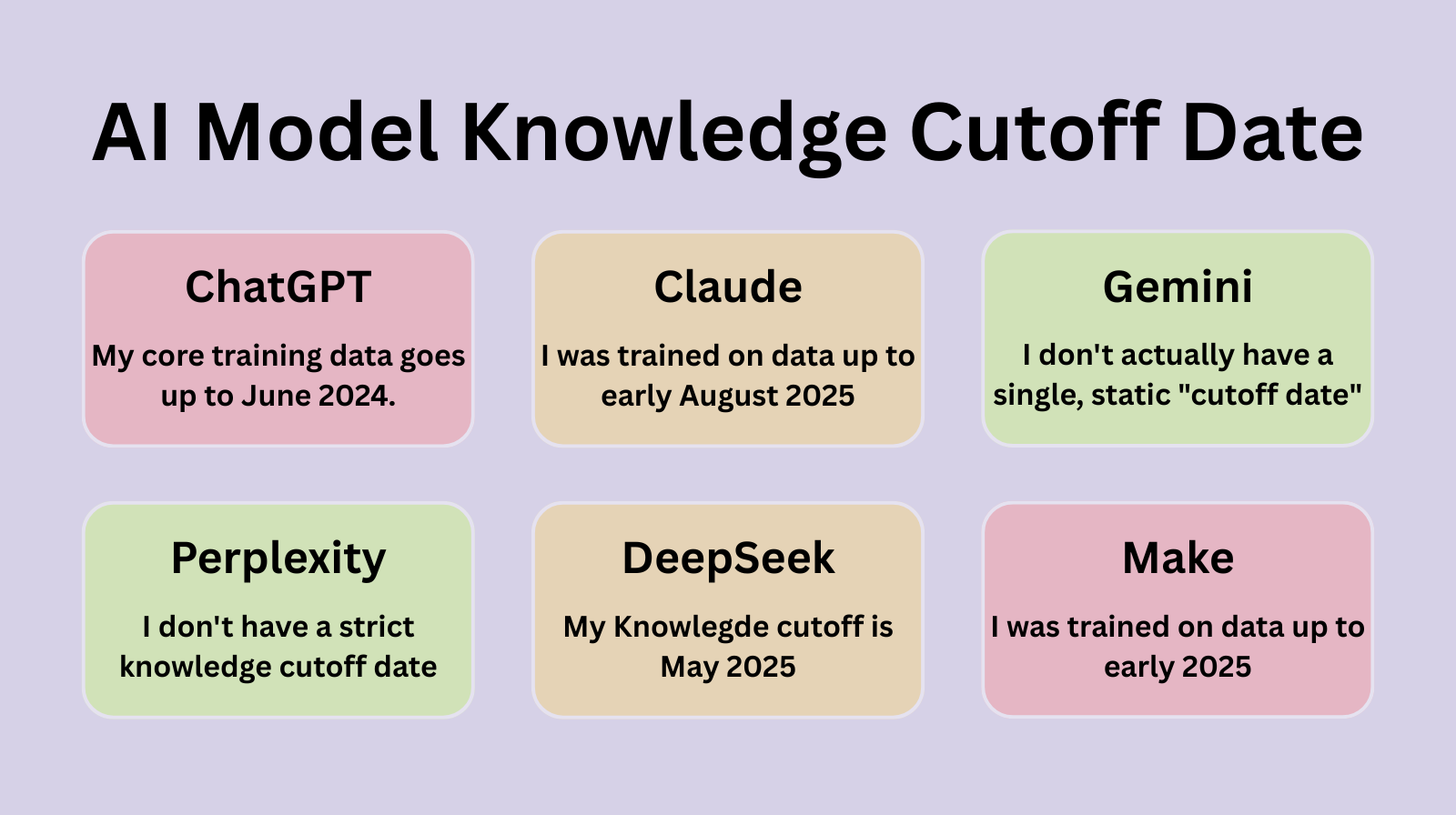
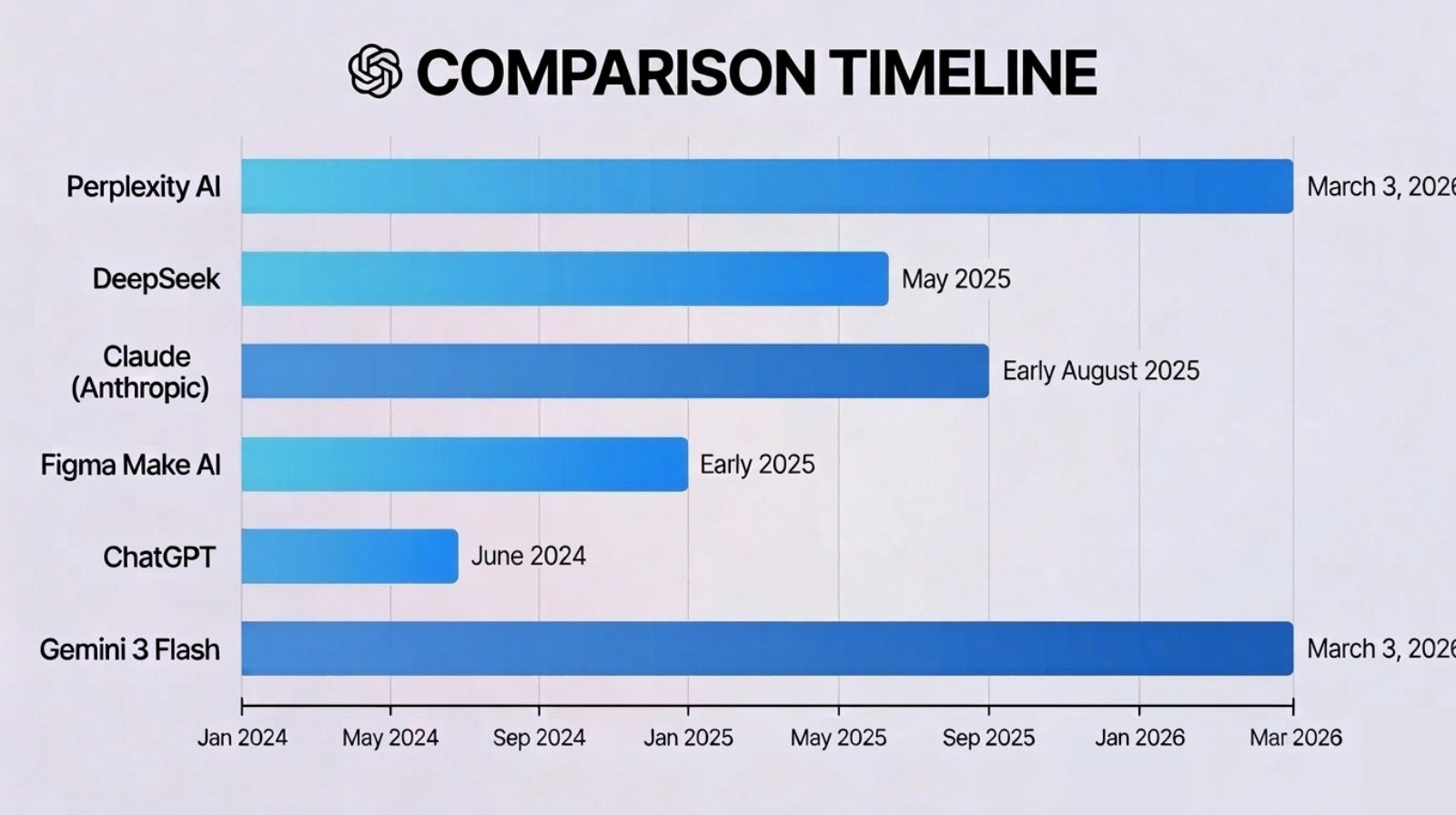
Knowledge Cutoff Dates: All Major AI Models Compared
Here's what the evidence reveals - cross-verified and fact-checked:
| AI Model | Knowledge Cutoff | How It Handles Updates |
|---|---|---|
| 🟢 Perplexity | No fixed cutoff | Powered by Grok 4.1; uses real-time web search for every query. Always current as of today. |
| 🔵 Claude (Anthropic) | Early August 2025 | Static training data to Aug 2025. Can use web search when enabled. Transparent about its cutoff. |
| ✨ Gemini 3 Flash | No fixed cutoff | Integrated with Google Search. Claims real-time access to 2026. Supplemented by live web retrieval. |
| 🟠 DeepSeek | May 2025 | Static cutoff at May 2025. Shows internal reasoning ('Thought for 2 seconds') before answering. |
| ⚫ Figma Make AI | Early 2025 | Specialized for React and Tailwind CSS web app generation in Figma. |
| 🟤 ChatGPT | June 2024 | Core training data to June 2024. Can look up latest updates if web browsing is enabled. |
Fact-Check Note: Perplexity describes itself as 'powered by Grok 4.1' in the screenshot - this is Perplexity's interface using xAI's Grok model as its backend engine. Perplexity itself is the product; Grok 4.1 is one of the underlying models it may route queries through. This is accurate as of early 2026.
Deep Dive: What Each AI Actually Said
1. Perplexity AI - 'No Strict Cutoff'
Perplexity boldly claims it has no strict knowledge cutoff date like traditional static models. Instead, it uses tools like real-time web search to fetch the latest information for every single query. As of March 3, 2026, it can reflect current events accurately - making it one of the most 'live' AI assistants available.
✅ Verdict: Accurate. Perplexity is fundamentally a retrieval-augmented AI - it searches the web before answering, which genuinely reduces the knowledge gap problem.
2. DeepSeek - 'May 2025'
DeepSeek transparently states its knowledge cutoff is May 2025. What's fascinating is its visible 'thinking' process - it shows its internal reasoning before delivering a clean, concise answer. This chain-of-thought transparency is a genuine differentiator for DeepSeek.
✅ Verdict: Accurate. DeepSeek R1/V3 series has a training cutoff around May 2025. The reasoning transparency shown is genuine.
3. Claude (Anthropic) - 'Early August 2025'
Claude clearly states a cutoff of early August 2025. It also proactively acknowledges the ~7-month gap to the current date (March 2026) and offers to use web search to fill the gap. This transparency-first approach is by design - Anthropic prioritizes honesty about limitations.
✅ Verdict: Accurate. Claude's training data extends to early August 2025.
4. Figma Make AI - 'Early 2025'
Figma Make's embedded AI is specialized - it exists primarily to help build web applications using React and Tailwind CSS inside Figma's development environment. Its knowledge cutoff is early 2025, but this matters less given its narrow, code-generation focus.
✅ Verdict: Accurate. Figma Make uses a focused AI optimized for front-end code generation, not general knowledge tasks.
5. ChatGPT - 'June 2024'
The screenshot shows a tool reporting a cutoff of June 2024 for its core training data. It also mentions personalization - suggesting this may be a custom GPT or a version of ChatGPT with memory enabled.
⚠️ Validation Note: OpenAI's GPT-4o has a training cutoff of April 2024, while GPT-4 Turbo's is December 2023. 'June 2024' may reflect a specific model variant or custom GPT configuration. Always verify which exact model version you're using.
6. Gemini 3 Flash - 'Real-Time via Google Search'
Gemini 3 Flash claims it doesn't have a single static cutoff date - instead, it's integrated with Google Search for real-time retrieval. It knows today is March 3, 2026, and can access current events as they happen - making it competitive with Perplexity in the 'live knowledge' category.
✅ Verdict: Accurate. Google's Gemini models are increasingly integrated with Search for grounding. However, for very niche breaking news, it recommends double-checking.
Real-World Consequences: When Cutoff Dates Bite
Here's why this isn't just a technical curiosity - it's a practical risk:
- Legal & Compliance: A lawyer using AI to research regulations that changed after the cutoff could provide incorrect advice.
- Medical Information: Healthcare guidance based on outdated studies could be genuinely harmful.
- Financial Decisions: Market data, interest rates, or company valuations from before the cutoff are now misleading.
- Technology Recommendations: Recommending a framework version that has since been deprecated or has known security vulnerabilities.
- Competitive Intelligence: A product strategy based on competitor info that's 12 months old.
- News & Current Events: Treating an AI summary as current news when it predates major world events.
🔑 The Golden Rule: Always match your task type to your AI tool. For current events -> use Perplexity or Gemini. For deep reasoning on stable knowledge -> Claude or DeepSeek. For code generation -> Figma Make excels in its niche.
Why Do Knowledge Cutoff Dates Change - And Why Do They Stay Fixed?
This is one of the most misunderstood aspects of AI. People wonder: 'If AI is so smart, why can't it just keep learning?' The answer is fascinating - and it reveals how fundamentally different AI training is from human learning.
Why Cutoff Dates Get Updated
AI companies periodically release new model versions with extended cutoff dates. This happens for several important reasons:
- Competitive Pressure: The AI race is fierce. OpenAI, Google, Anthropic, and others must regularly update models to stay relevant. A model with a 2-year-old cutoff becomes commercially unviable.
- Scheduled Retraining Cycles: Most top-tier AI labs run major training cycles every 6–12 months. Each new cycle incorporates a more recent data snapshot, pushing the cutoff date forward.
- User Demand & Feedback: When millions of users report that an AI 'doesn't know' about major recent events, companies are pressured to update sooner.
- Infrastructure Improvements: As compute becomes cheaper and training pipelines more efficient, updating models becomes faster and more cost-effective.
- Safety & Alignment Research: New versions incorporate the latest safety techniques - meaning a model update isn't just about knowledge, it's about being safer too.
📅 Real Example: Claude's cutoff advanced from April 2024 (Claude 3) -> January 2025 (Claude 3.5) -> August 2025 (current Claude). Each new version pushed the knowledge boundary forward. This is normal, expected, and ongoing.
Why Cutoff Dates Stay Fixed - The 6 Core Limitations
Even if an AI company wanted to give a model 'live' knowledge, it's architecturally very hard - and comes with serious trade-offs.
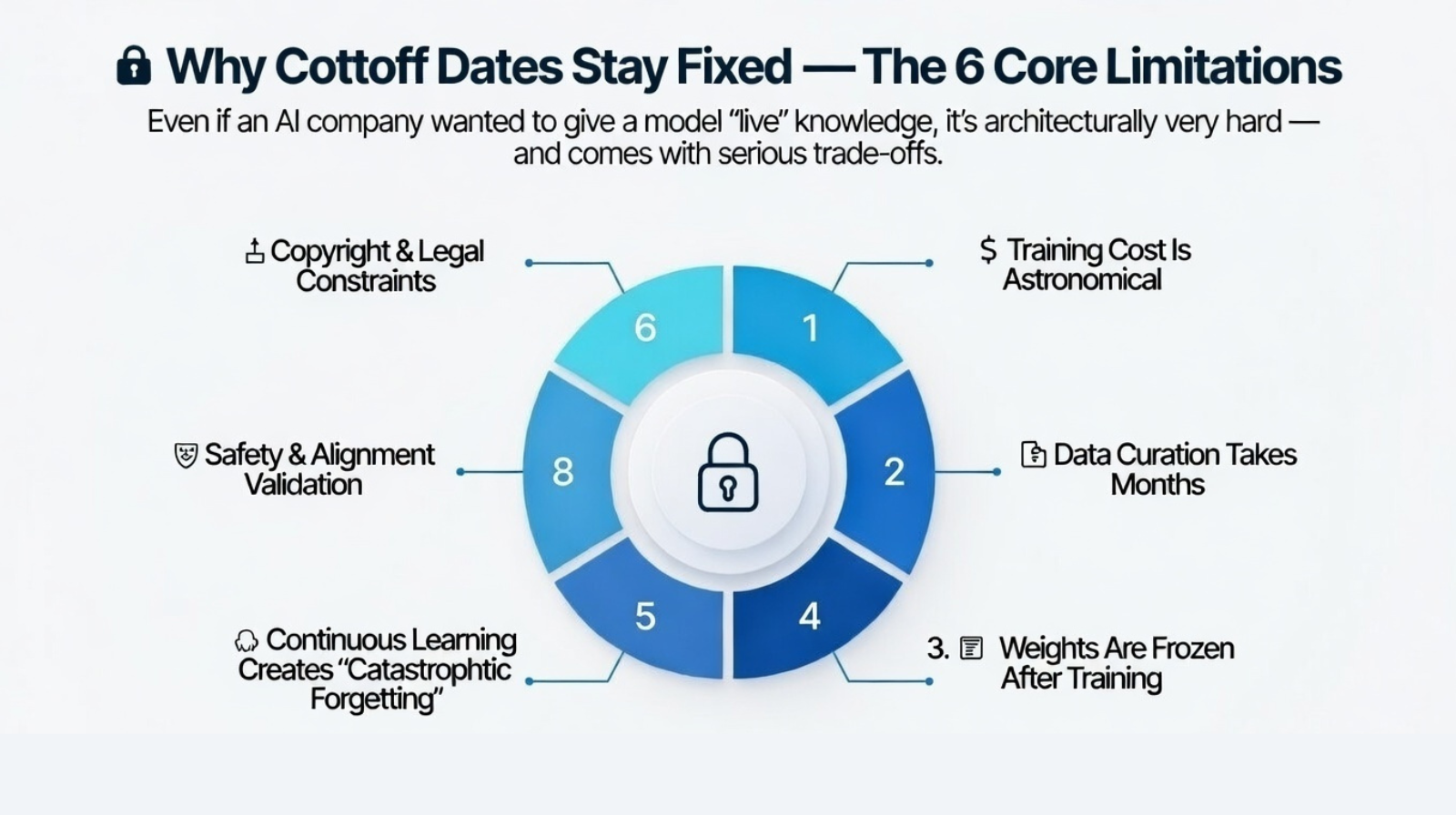
1. 💸 Training Cost Is Astronomical
Training a frontier LLM costs tens to hundreds of millions of dollars and consumes enormous GPU compute. You simply cannot retrain a full model weekly or even monthly. Each training run is a massive, deliberate, expensive operation - not a button you press lightly.
2. 🗂️ Data Curation Takes Months
You can't feed an AI 'everything on the internet today.' Training data must be carefully collected, cleaned, filtered for quality, deduplicated, checked for harmful content, and formatted correctly. This data pipeline itself takes months - meaning by the time training starts, the data is already somewhat outdated.
3. 🔐 Weights Are Frozen After Training
Once an LLM's training is complete, its weights - the billions of numerical parameters that encode knowledge - are frozen. The model does not 'learn' during conversations. Every chat session starts from the same fixed state. Injecting new knowledge post-training requires either fine-tuning or a completely new training run.
4. 🧠 Continuous Learning Creates 'Catastrophic Forgetting'
Neural networks have a known problem: if you keep training them on new data without full retraining, they tend to 'forget' what they previously learned - a phenomenon called catastrophic forgetting. This makes incremental online learning technically challenging and potentially harmful to model quality.
5. 🛡️ Safety & Alignment Validation
Before any model is released publicly, it undergoes extensive safety evaluation - red-teaming, bias testing, harmful output detection, and alignment validation. This process alone can take weeks to months. You can't rush it just because the training data is fresh.
6. ⚖️ Copyright & Legal Constraints
Not all internet content can legally be used for training. Licensing agreements, copyright law, and data privacy regulations (GDPR, CCPA) restrict which data can be harvested. Curating legally compliant training datasets is a complex, ongoing challenge - not just a technical one.
What Does an AI Actually Do When You Ask Something Beyond Its Cutoff?
When you ask an AI about something that happened after its training cutoff, it doesn't crash or say 'error.' It does something far more nuanced - and sometimes problematic.
Scenario 1: The AI Doesn't Know It Doesn't Know 😬
This is the most dangerous scenario. The AI has no direct information about the event, but it has enough related context to construct a plausible-sounding answer. It doesn't flag uncertainty. It just... answers. Confidently.
Example: You ask about the outcome of an election that happened 3 months after the AI's cutoff. The AI might describe the political landscape as it was before the election and present it as current fact - without ever signaling it's outdated.
⚠️ This is called 'hallucination by omission' - the AI doesn't lie, but it omits the crucial caveat that its information is outdated.
Scenario 2: The AI Honestly Acknowledges the Gap ✅
Well-designed AI systems - like Claude - are trained to recognize when a query likely touches post-cutoff territory and proactively say so. You'll see responses like:
"My training data goes up to August 2025. For the most current information on this topic, I recommend checking recent news sources - or I can use web search to look it up for you."
This is the ideal behavior - transparency about limitations paired with an active offer to help bridge the gap.
Scenario 3: The AI Makes a Confident 'Best Guess' 🎲
For some questions, the AI extrapolates from trends it knows. If you ask about a technology trajectory or market direction, it might make a projection based on patterns in its training data - and present it with moderate confidence. Sometimes these guesses are surprisingly accurate. Other times, they're completely wrong because of unexpected events (a pandemic, a sudden market crash, a regulatory change).
Scenario 4: The AI Uses Web Search to Fill the Gap 🔍
This is the most powerful modern solution. Tools like Perplexity, Gemini (with Search), ChatGPT (with browsing), and Claude (with search enabled) can reach outside their training data and retrieve real-time information. The AI essentially becomes a reasoning layer on top of live search results.
Behavior Risk Matrix
| Situation | AI Behavior | Risk Level | What You Should Do |
|---|---|---|---|
| Topic is post-cutoff, AI is unaware | Answers confidently with outdated info | 🔴 HIGH | Always verify with current sources |
| Topic is post-cutoff, AI flags it | Admits limitation, offers to search | 🟢 LOW | Trust, but confirm with a live source |
| AI makes a trend-based guess | Projects forward with moderate confidence | 🟡 MEDIUM | Cross-check with real data |
| AI has web search enabled | Retrieves live data, reasons over it | 🔵 VERY LOW | Check that cited sources are reliable |
The Technical Truth: What Happens Inside the Model
When an LLM receives a query about something beyond its training data, here's what actually happens at a technical level:
-
Token Prediction Still Runs: The model generates a response token-by-token based on the probability distributions learned during training. It has no internal 'flag' that says 'I don't know this specific thing.'
-
Related Patterns Fill the Gap: The model finds the closest related patterns in its training data and generates a coherent response based on those patterns - even if those patterns don't apply to the new situation.
-
Context Window is the Lifeline: If you paste current information INTO the conversation (like a news article), the model CAN reason about it correctly. It uses in-context information over its trained knowledge - which is why providing context with your questions dramatically improves accuracy.
-
Retrieval-Augmented Generation (RAG) is the Solution: The industry's answer to this limitation. RAG systems retrieve relevant, current documents first, then feed them to the model as context before generating a response. This is exactly what Perplexity and Gemini do with web search.
💡 Pro Tip for Advanced Users: You can partially overcome an AI's knowledge cutoff right now - without web search. Simply paste the relevant current information (a news article, a document, a data table) directly into your conversation. The AI will reason about YOUR provided context rather than relying solely on its training data. This works with any AI model.
How to Protect Yourself: 5 Practical Tips
1. Always Ask Your AI Its Cutoff Date
Before any important task, ask: "What is your knowledge cutoff date?" Most models will tell you honestly - as this blog demonstrates.
2. Cross-Reference Time-Sensitive Facts
For anything involving dates, events, laws, prices, or people in current roles - verify with a current web source. Use your AI to understand and synthesize, not as the sole source of truth.
3. Use the Right Tool for the Right Job
Need real-time information? Use Perplexity or Gemini (with Search enabled). Need deep reasoning, coding help, or document analysis? Claude and DeepSeek excel. Need to build a UI fast? Figma Make is purpose-built.
4. Enable Web Search Features When Available
Most AI platforms - including Claude, ChatGPT, and Gemini - offer optional web browsing features. Always enable these when working on current events or recent developments.
5. Treat AI Outputs as a Starting Point, Not an Endpoint
AI is your powerful research assistant, not your final authority. The best AI users are the ones who combine AI's speed and breadth with their own critical thinking and current knowledge.
The Future: AI That Never Goes Stale?
The trend is clear - the industry is moving toward Retrieval-Augmented Generation (RAG) and real-time search integration. Perplexity and Gemini are leading this shift, while ChatGPT and Claude offer web search as optional features.
We're entering an era where the distinction between 'trained knowledge' and 'live knowledge' will blur. Future AI systems may continuously learn and update - though this brings its own challenges around accuracy, bias, and information verification.
🚀 The Bottom Line: Knowledge cutoff dates are not a bug - they are an architectural feature of how LLMs are built. Understanding them doesn't make you distrust AI. It makes you use AI smarter. And in 2026, smart AI use is a genuine competitive advantage.
Conclusion
Knowledge cutoff dates are a fundamental aspect of how AI models work, and understanding them is essential for anyone using AI tools professionally. The comparison across major AI platforms reveals a clear divide: some models like Perplexity and Gemini offer real-time access through web search, while others like Claude and DeepSeek maintain static cutoffs but excel in reasoning and specialized tasks.
The key to effective AI usage lies in matching the right tool to the right task, always verifying time-sensitive information, and treating AI outputs as starting points rather than final authorities. As the industry evolves toward more RAG-based systems, the gap between trained knowledge and live knowledge will continue to narrow.
Key Takeaways
- Perplexity & Gemini - Real-time web access - closest to 'no cutoff'
- Claude - August 2025 cutoff - transparent and honest about limitations
- DeepSeek - May 2025 cutoff - unique chain-of-thought visibility
- Figma Make - Early 2025 - specialized for UI/code generation
- ChatGPT - Varies by model - always check which version you're using
- Cutoff dates stay fixed due to cost, data curation time, frozen weights, catastrophic forgetting, safety validation, and legal constraints
- When asked out-of-cutoff questions, AI may answer confidently with outdated info - always verify
- You can bypass cutoff limits today by pasting current information directly into your AI chat
- Always ask. Always verify. Always use the right tool for the right task.